Beyond Numbers: Building Data Literacy Through Philosophical Foundations and Real-Time Learning
The Bottom Line Up Front: Data literacy isn't just about reading charts or calculating averages. It's about developing a fundamental way of thinking rooted in centuries of philosophical inquiry about knowledge, causation, and decision-making. The most effective data literacy programs combine these deep conceptual foundations with innovative, real-time learning approaches that meet people at their precise moments of need.
The Origin Story: Where Data Literacy Really Begins
When we talk about data literacy, we often start with spreadsheets and dashboards. But the true foundation lies much deeper, in questions philosophers have been wrestling with for millennia: How do we know what we know? What can we trust about the patterns we observe? How do our experiences shape our understanding of reality?
"Data is more than a mere commodity in our digital world. It is the ebb and flow of our modern existence," write Angelika Klidas and Kevin Hanegan in Data Literacy in Practice (Packt Publishing, 2022). This poetic description captures something essential about data's role in human understanding—it's not just information, but the very substrate through which we make sense of our world.
The philosophical roots of data literacy stretch back to empiricism, the school of thought that, according to the Stanford Encyclopedia of Philosophy, "holds that true knowledge or justification comes only or primarily from sensory experience and empirical evidence." When we teach someone to look at data, we're actually teaching them to be empiricists—to trust observations over assumptions, to build understanding from the ground up through careful attention to evidence.
This empirical foundation matters more than we might initially think. Every time someone looks at a chart and asks "What does this pattern tell us?" they're engaging in inductive reasoning—what The Decision Lab defines as the process of "forming a generalization based on a set of specific observations." They're participating in a tradition of inquiry that connects them to Francis Bacon's scientific method, David Hume's skeptical investigations, and contemporary data scientists working on causal inference.
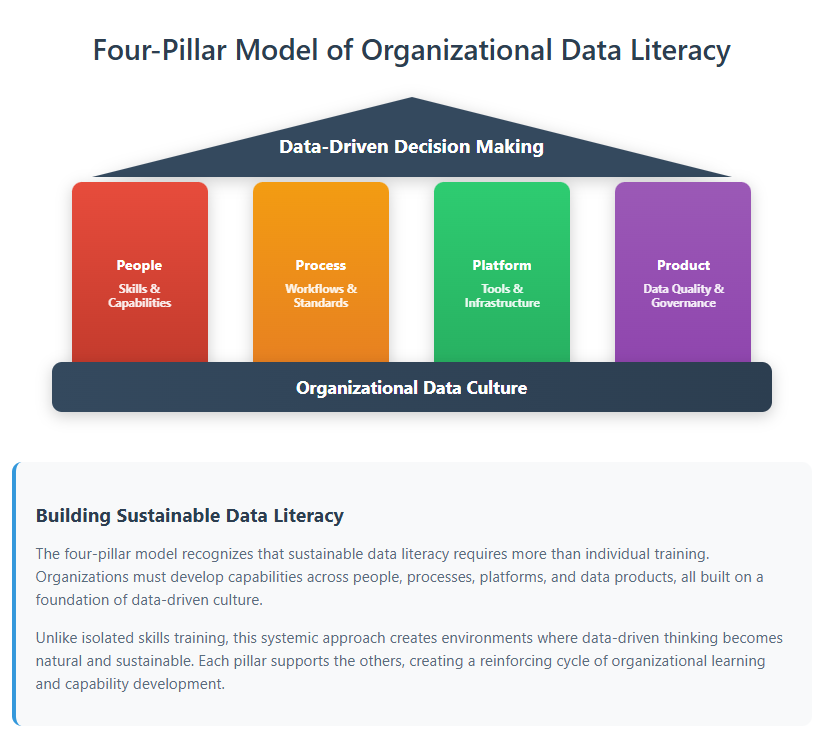
The Four-Pillar Foundation of Organizational Data Literacy
Modern data literacy programs often focus on individual skills—teaching people to use Excel or understand statistical concepts. But the most effective approaches recognize that data literacy is fundamentally organizational. The four-pillar model from "Data Literacy in Practice" provides a framework for organizations to transform data into insights through a systematic approach that addresses culture, not just capability.
These pillars create the scaffolding for genuine data-driven thinking. They recognize that isolated technical training often fails because it doesn't address the environmental and cultural factors that determine whether people actually use data in their decision-making. Just as empirical philosophers understood that knowledge doesn't exist in a vacuum but emerges through communities of inquiry, effective data literacy programs understand that data-driven thinking flourishes within supportive organizational ecosystems.
The genius of this approach lies in its recognition that, as Klidas and Hanegan emphasize, "organizational data literacy" matters more than just individual skills. When we create environments where data-driven thinking is expected, rewarded, and supported with the right tools and processes, individual capability development becomes both easier and more meaningful.
The Teachable Moment Revolution: Learning in Real-Time
Here's where traditional data literacy education often fails: it treats learning as a front-loaded event rather than an ongoing, contextual process. The authors of The Decoded Company (Portfolio, 2014) by Leerom Segal, Aaron Goldstein, Jay Goldman, and Rahaf Harfoush discovered something crucial about how people actually learn to work with data effectively. As they write, "It's ironic that we collectively know so much about the psychology of learning, through generations of studying schools and natural learning, and yet we're still delivering ineffective, one-size-fits-all training programs."
The solution lies in what the Decoded Company authors call "teachable moments"—"the exact instant when an employee should receive training, delivered in a customized way that caters to that employee's needs." This concept transforms how we think about data literacy development. Instead of front-loading people with abstract concepts they might use someday, we provide targeted learning exactly when they encounter specific data challenges in their work.
Consider how this might work in practice. An employee is looking at quarterly sales data and notices an unexpected pattern. Traditional training would have taught them general concepts about trend analysis weeks or months earlier. Real-time learning provides contextual guidance right at the moment of curiosity: "You're looking at what appears to be a seasonal variation. Here's how to test whether this pattern is statistically significant, and here are three questions you should ask about potential confounding factors."
This approach aligns beautifully with how empirical knowledge actually develops. Philosophers like John Stuart Mill understood that, as described in the Stanford Encyclopedia of Philosophy's analysis of his work, "knowledge of any kind is not from direct experience but an inductive inference from direct experience." Learning happens through the active process of making sense of specific observations, not through passive absorption of general principles.

The Philosophy of Causal Thinking in Data Practice
Most data literacy programs teach correlation analysis but give insufficient attention to causal reasoning. This represents a massive missed opportunity, because "causal knowledge and reasoning can help decision makers predict the consequences that might result from the different courses of actions they could take."
Understanding causation versus correlation isn't just a statistical nicety—it's fundamental to using data for decision-making. As research published in The Handbook of Causal Analysis for Social Research demonstrates, "causal knowledge and reasoning can help decision makers predict the consequences that might result from the different courses of actions they could take."
When someone looks at data showing that their marketing campaign coincided with increased sales, they need to think causally: Did the campaign cause the increase, or did both the campaign timing and sales increase result from some other factor?
This type of thinking requires what cognitive scientists call causal modeling—the ability to, as described in the Open Encyclopedia of Cognitive Science, "build internal causal models that allow them to simulate possible scenarios and hence to compare what actually happened against other counterfactual possibilities." It's sophisticated reasoning that goes far beyond basic data manipulation skills.
The fascinating research emerging around causal reasoning and decision-making reveals something crucial. As published in Cognitive Research: Principles and Implications, "causal information could aid decision-making by providing supporting reasons for a choice, clarifying the valuation of options, or serving as the basis of task information feedback." In other words, when people understand not just what the data shows but why it might be happening, they make better decisions.

Knowledge Management as Learning Infrastructure
One of the most overlooked aspects of effective data literacy programs is the role of knowledge management systems. Traditional training assumes that once someone learns a concept, they'll remember and apply it correctly. But real-world data work involves constantly encountering new situations that require both foundational understanding and specific procedural knowledge.
The solution involves building what the Decoded Company authors call "engineered ecosystems"—environments where the tools themselves become teachers. As they put it, "Technology can be a coach, personalizing processes to the individual based on experience and offering training interventions precisely at the teachable moment."
This might involve documentation systems that surface relevant guidance based on the type of analysis someone is conducting, video libraries organized around specific decision contexts, or collaborative platforms where people can easily access the reasoning behind previous data-driven decisions. The key insight is that learning support should be embedded in the workflow, not separated from it.
Such systems recognize something important about human cognition: we don't store information in isolation but as part of networks of related knowledge. When we can access not just the "how" but also the "why" and "when" of data analysis techniques, we develop more robust and transferable skills.
Beyond Surface Learning: The Maturation Path
Most data literacy programs focus on basic competencies—reading charts, understanding averages, recognizing trends. But genuine data literacy involves much more sophisticated thinking. It requires developing what we might call "epistemic humility"—an understanding of what data can and cannot tell us, and how our own biases and assumptions shape our interpretations.
This mature approach to data literacy draws from the skeptical tradition in philosophy. David Hume's investigations, as analyzed in the Stanford Encyclopedia of Philosophy, showed that "our belief in cause and effect relationships cannot be rationally justified through either reason or experience" alone, but emerges through habits of thought shaped by repeated observation. This insight should humble anyone working with data and make them more thoughtful about the limits of their conclusions.
Advanced data literacy also involves understanding how, according to research in Cognitive Research: Principles and Implications, "causal information could potentially reduce cognitive load by acting as heuristics that simplify decisions or by helping to overcome limits on working memory." When people understand the underlying causal relationships in their domain, they can make better decisions even with limited information.
The maturation path for data literacy therefore involves moving from mechanical skills (calculating percentages, creating charts) through interpretive skills (recognizing patterns, identifying anomalies) to epistemic skills (understanding uncertainty, reasoning about causation, recognizing the limits of available evidence).

Designing for Different Learning Contexts
One size definitely does not fit all when it comes to data literacy education. Research on causal reasoning published in Cognitive Research: Principles and Implications reveals that "individuals without experience are aided by causal information, while individuals with experience do worse" when given additional information. This finding has profound implications for how we design learning interventions.
For novices in a domain, providing rich causal models and detailed explanations enhances decision-making. They benefit from external cognitive support that helps them understand the relationships between different variables. For experts, additional information can actually interfere with their intuitive understanding and lead to worse decisions.
This suggests that mature data literacy programs need multiple pathways. Beginners need comprehensive scaffolding that helps them build mental models of how different factors relate to each other. Intermediate learners need targeted skill development in specific analytical techniques. Advanced practitioners need philosophical grounding that helps them recognize the limits and assumptions built into their analyses.
The key insight is that learning needs change not just based on general skill level, but based on domain-specific experience. Someone might be a sophisticated analyst in their area of expertise but need beginner-level support when working with data from an unfamiliar domain.
The Integration Challenge: From Fragments to Frameworks
Perhaps the biggest challenge in current data literacy education is fragmentation. People learn Excel in one context, statistics in another, visualization principles in a third setting, and domain knowledge in their day-to-day work. They rarely get help integrating these different types of knowledge into coherent frameworks for thinking about problems.
Effective data literacy education needs to be more like learning to be a detective than learning to use tools. Detectives don't just know how to collect fingerprints or interview witnesses—they develop frameworks for thinking about evidence, causation, and uncertainty that help them integrate different types of information into coherent narratives.
This integration happens most effectively when learning is anchored in real problems that learners care about solving. When someone is trying to understand why customer satisfaction scores dropped last quarter, they're motivated to learn whatever analytical techniques will help them find answers. The problem provides the integrative framework that gives meaning to individual skills.
The Decoded Company concept of "Real-time learning: acquiring a skill exactly when you need to" becomes particularly powerful when it's embedded in authentic problem-solving contexts. The learner isn't just acquiring isolated techniques but building their capacity to think systematically about evidence and inference.
The Future of Data Literacy: Synthesis and Scale
The future of data literacy education lies in synthesizing insights from philosophy, cognitive science, organizational learning, and technology design. We need approaches that are simultaneously:
Philosophically grounded: Helping people understand the deeper questions about knowledge, evidence, and inference that underlie all data work.
Contextually responsive: Delivering learning support at precisely the moments when people need it, tailored to their specific situations and experience levels.
Organizationally embedded: Creating cultures and systems that support data-driven thinking rather than just data-related skills.
Progressively sophisticated: Providing pathways for people to develop from basic competencies through advanced epistemic skills.
This vision requires moving beyond the current fragmented approach to data literacy education. Instead of separate courses on statistics, visualization, and domain knowledge, we need integrated learning environments that help people develop robust frameworks for thinking with data.
The stakes are high. In a world where, as Klidas and Hanegan write, "data is the ebb and flow of our modern existence," data literacy becomes a fundamental civic skill. People who can't think critically about evidence, understand uncertainty, or reason about causation will be increasingly disadvantaged in both their professional and personal lives.
But when we get this right—when we help people develop genuine data literacy that connects technical skills with philosophical understanding—we create something much more valuable than job-relevant competencies. We create citizens who can participate thoughtfully in democratic discourse, professionals who can navigate complexity with wisdom, and human beings who can make better decisions about the things that matter most to them.
The path forward requires patience, sophistication, and a willingness to learn from disciplines beyond data science and technology. It requires recognizing that data literacy is fundamentally about developing better ways of thinking, not just better ways of manipulating numbers. And it requires creating learning environments that honor both the complexity of real-world problems and the capacity of human beings to grow into more thoughtful and capable reasoners.
This blog post is part of a series exploring the deeper dimensions of data literacy. Future posts will examine specific implementation strategies, measurement approaches, and case studies of organizations that have successfully built cultures of data-driven thinking.